
Cheap Code
Reproducible, Not Reusable

Time was, a historian who wanted to see what was in a probate had to read the probate.

Recently I was working with a 900-page probate of John McDonogh, an enslaver and landlord in New Orleans who died in 1850. The probate was expensive to produce. Every page was cleanly laid out in a grid, written in an impressive secretary hand. And though I can read such old-fashioned script, doing so is not the same as reading print. Even if it were in print, keeping track of 900 pages of entries and calculations would be taxing. Simply reading the document would take weeks. Copying out the entries for verification in a spreadsheet would be herculean. Even with an ample research budget, subcontracting the work to undergraduate RAs would consume months.
I had a very basic, but important question: how much of his wealth was in enslaved people compared to his other property?
To get that answer would have taken months of work. So much work, in fact, that I probably would never have done it.
In the era of AI, a very different approach is possible. You can write cheap code. You can get the answers that you want.
By cheap code, I mean hyper-specific, one-off code written for a singular purpose—like making sense of a 900-page probate. Traditional digital humanities tools required either general-purpose software too rigid for the variation in historical documents, or years of custom development. Only human brains could handle the idiosyncrasies. But today, with AI, you don’t need general-purpose software for reading probates. You can write software to read just this document.
Here is what I actually did. First I scanned the probate with a CZUR scanner—about an hour’s work. Then I used the ChatGPT API to perform OCR and extract the well-structured pages into well-structured JSON. This step required real attention to prompt engineering: I wanted both raw and corrected OCR, French originals alongside English translations, and special attention to the categories I cared about—land, buildings, enslaved people, financial assets. For each entry I asked for names, value, location, and a best-guess latitude and longitude. I used the batch API to keep costs down. The whole run cost about what you’d pay for lunch.
Once I had the JSON, I turned to Claude. I showed it sample files and asked it to write a script that extracted everything into a spreadsheet. That alone was extraordinarily useful for getting a handle on thousands of entries. Next I asked it to verify the arithmetic: on every page, a running total recorded the estate’s cumulative value, and I wanted to check every page’s actual summed entries against that figure. There were minor discrepancies but nothing significant. (And I did this same exercise in Notebook LLM with some inaccurate, non-reproducible results. When counting, always use offline code!)
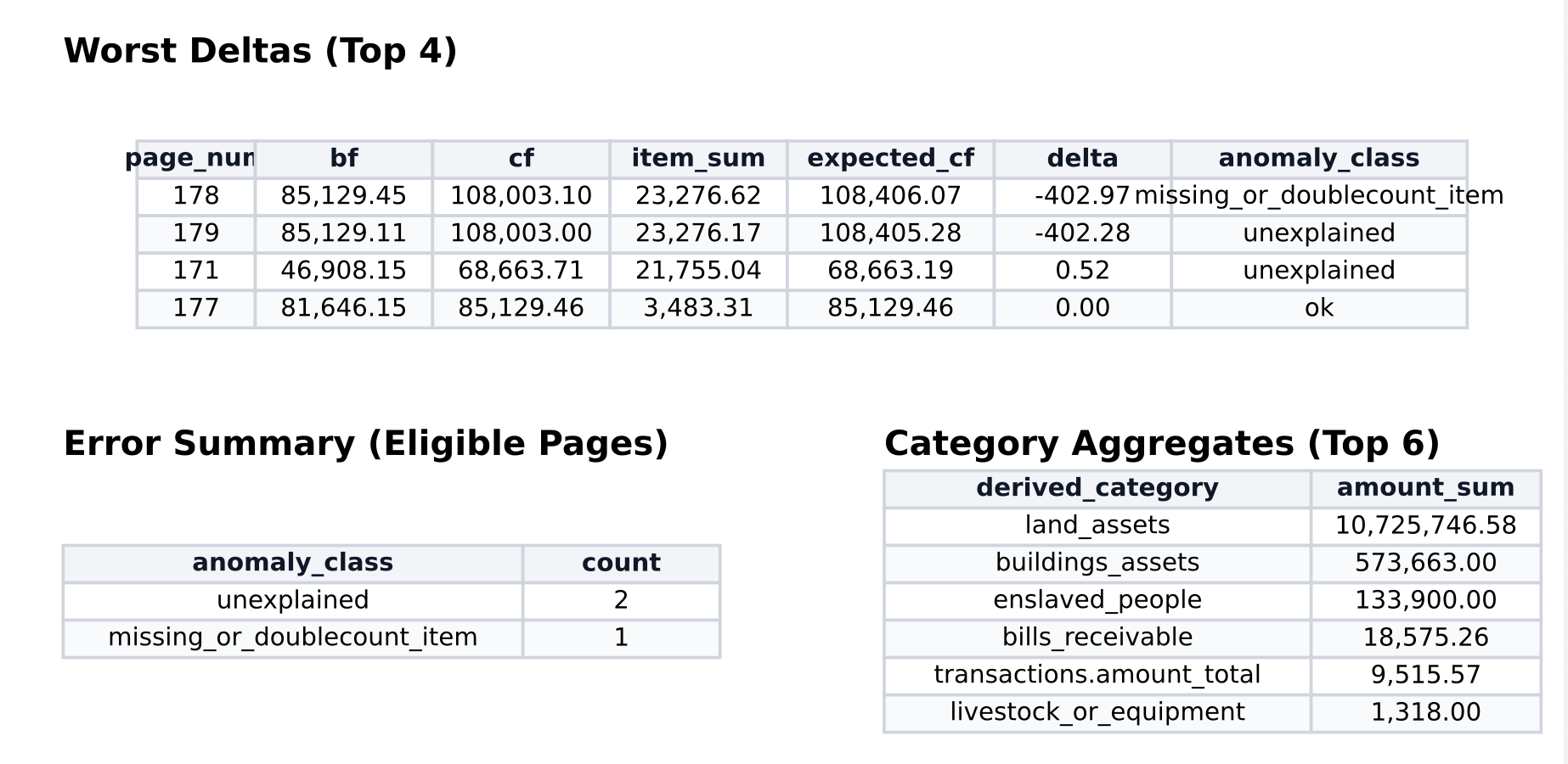
From there it was straightforward to generate summary statistics—mean, median, range—and visualizations of how the estate’s value was distributed across asset classes. I could see at a glance exactly how much of McDonogh’s estate was held in financial instruments, in land, in buildings, and crucially, in people.
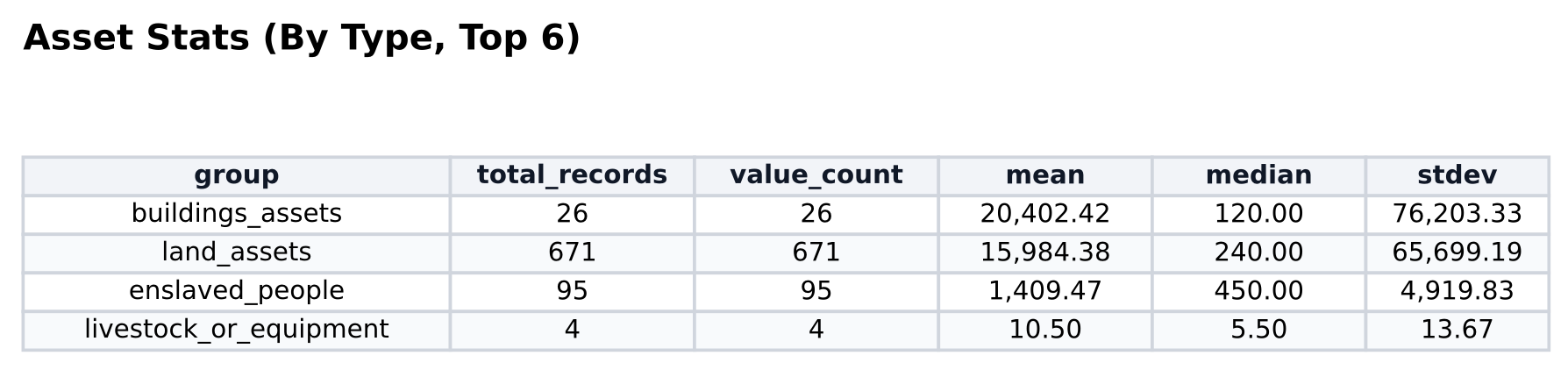
The people enslaved by John McDonogh emerged from the record with clarity. Ages. Names. Occupations. Locations. Every individual could be found and examined. New stories could be told of their lives. This is, of course, the moral center of the project: a slaveowner’s meticulous accounting of human property makes it possible to recover some part of their humanity. At the very least, their names.
Writing this software took about thirty minutes. Iterating on what I wanted—a graph of age vs value vs gender —took another half hour. The code was not elegant, not generalizable, not meant to be shared or preserved. It was cheap code, and that was precisely the point. You could run it and get reproducible results, which is fantastic, but you could not use with another probate.
The deeper methodological point deserves to be stated clearly. This approach is reproducible but not reuseable. In the pre-AI days, software code was both reproducible and reuseable, and had high costs. For many documents, especially bureaucratic documents, cheap code is not a compromise—it is the only realistic path to analysis.
For the first time, I could calculate the complete asset mix of a prominent New Orleans slaveowner: what he held in land, in buildings, in financial instruments, and in human beings. I could do it in an afternoon. The 900-page probate that would once have demanded so many months of my time that I would never do it, gave me the answer in a couple hours.
The question is not whether to write the scripts, it is which documents we should analyze first.
Code: GitHub folder
Method + audit logic: AUDIT_LOGIC.md
Repository: computational_history
I've been waiting for someone to jump on this and props to Louis Hyman for seeing it, doing it, and sharing it with the world.
the future of historical scholarship is going here: training grad students first in how the data collection/scanning works so they understand the issues/nuances/problems in the data sets, then training on code and stats discussions, all converging on some kind of consensus on coding best practices. Perhaps that is already happening in pockets I'm unaware of (like the Summer Camp Louis leads).
Feels like the shift with be to history what GPS was to Geography, or computational computing's effect on Astronomy... a kind of before/after moment where you can't make progress in the field without mastering the new tools.
2 Questions:
1) how long a lag before this process becomes standardized? Does it stay disaggregated and innovative, or do you think it will tend toward some AHA or other sub-disciplinary group trying to create best practices?
2) how much funding would it take to digitize all probate records? Thinking here of the lifetime of work Loren Schweninger undertook to get probate records in the US South. An army of graduate students could/should digitize the whole thing into OCR-ready files, right? Much of it is in microfilm already. Theoretically you could then unearth immensely valuable insights about economic mobility (both inter- and intragenerational, ethnic, racial, etc.), especially if you could overlay w/ immigration records, bankruptcy filings, etc. Who went up, down, sideways, and how that differed by geography, for instance.
The data collection and OCR files are a one time event that could be "reusable" for all scholars, and the individual codes put on top of that would truly lead to new "repeatable" insights.
All this just to say, Bravo! Here is to more of this. I'm following this Substack w great interest. Thanks for sharing.
Hi Louis. We should chat. Perfect example of quick vibe coding. Pretty close to one of my potential use cases [Estate and Probate Inventories] in my recent substack [https://generativelives.substack.com/p/history-vibe-coding]. You might want to check out some of the topics we are looking at in the AI and History collaboratory I convene [as a public historian], particularly our recent session on Cowork for Historians, in which we explored creating and using HISTORY-SKILLS.md files to encode workflows for historical research. [https://github.com/ai-and-history-collaboratory/ai-and-history-collaboratory]