
Reading for Structure
It handled the reading; we handled the thinking.

If you wanted to transcribe a handwritten register, you had to transcribe it. Not skim it or glance through it, but sit with the document and work through it line by line. When the handwriting was difficult, you learned the hand. When the spelling was inconsistent, you learned the habits of the writer. If the document ran to hundreds of pages, you prepared yourself for weeks of slow work.

Historians have always done this kind of labor, and so have graduate students, research assistants, and archivists. The work can be tedious, but it produces searchable texts, datasets, and indices that allow us to see patterns that would otherwise remain hidden. At the same time, this labor quietly shapes the boundaries of historical inquiry. The sheer effort required to process a document often determines which sources historians pursue and which they leave aside.
I encountered a document that illustrates this problem while working with historian Philip Herrington. During research at the Henry Ford Archives, Philip came across a guest register from the Hermitage Plantation, just outside Savannah, Georgia. The book records visitors between 1933 and 1935 and runs to 159 pages. Each line contains a date, a visitor’s name, and a hometown, producing thousands of entries written by hundreds of different hands.
The register is historically valuable because it offers a rare window into plantation tourism in the early twentieth century. Visitors arrived from across the United States, particularly from northern cities, and their entries reveal patterns of travel and mobility in the Jim Crow era, when plantation landscapes were increasingly repurposed as heritage sites. But the document also presents the kind of practical difficulty historians know well. The handwriting varies widely, some entries are careful while others are hurried, and ditto marks appear where locations repeat. Ink colors change across the pages, and occasionally several people sign on the same line.

To answer even simple questions about the register—where visitors were coming from, whether particular cities appeared repeatedly, how visitation changed over time—the information had to be structured as data. The traditional approach would be clear enough: transcribe the book, enter each line into a spreadsheet, verify the entries, and standardize the locations. Many historians have undertaken precisely this kind of work. Even at a steady pace, though, the process could easily consume weeks or months of labor, which in practice means that many such documents are never fully transcribed nor eventually made accessible to others.
Artificial intelligence tools offer a different approach, though not the one that gets the most attention. Writers like to talk about AI “transforming” historical research, usually meaning something dramatic about automated interpretation. That overstates the case; an LLM does not interpret the past. What it can do is assist with the mechanical work of recognizing and structuring text—provided the historian teaches it how to behave.
LLMs are not designed to read handwritten guest registers. When I first uploaded pages from the Hermitage register without detailed instructions, the model invented names that weren’t on the page and merged separate entries into single lines. To obtain reliable results, the historian has to provide something the model lacks: instructions grounded in how we actually read these documents.
In practice this means defining the task with the kind of specificity we would use when training a new research assistant. Each page of the register was scanned and uploaded to a model capable of processing images. Rather than asking the system simply to “transcribe the page,” the prompt described the document and its structure in detail. The model was told that it was working with a handwritten guest register and that each row contained a date, a visitor name, and a location. It was instructed not to guess when handwriting was unclear and to flag uncertain entries instead. The output format was specified in advance: a table with the columns Date, Visitor, and Location.
Historians will recognize the logic immediately. We explain what kind of document someone is looking at, identify patterns they should expect to see, warn them about ambiguities, and show them the format in which the results should be recorded. The difference is that the “someone” here processes a page in seconds rather than minutes.
Once those instructions were refined, the model began producing usable output. Each page returned tab-delimited text that could be copied into a transcription platform and reviewed by a human editor. The transcription was not perfect: names were occasionally misread and locations sometimes required correction. But starting from a rough transcription rather than a blank spreadsheet changed the nature of the work. Instead of entering thousands of lines manually, we reviewed and corrected what was already there. The process had shifted from creation to verification, and what might have taken months was compressed considerably.
This leads to a methodological point that historians may initially find uncomfortable. For many research questions, “good enough” data is enough. Historians are trained to value fidelity in transcription, and rightly so. Yet the level of precision required always depends on the question being asked. If the goal is a diplomatic transcription of a manuscript, every mark matters. But if the goal is to analyze visitor origins, travel frequency, and geographic networks, then a structured transcription that is mostly correct can be sufficient, especially when the alternative is no transcription at all.
What keeps this honest is that the historian does the interpretive work. Once the Hermitage register had been transcribed and cleaned, the results became immediately useful. Entries could be sorted by city, mapped geographically, and examined for clusters of visitors from particular regions. Patterns that had been buried in the handwriting of the original ledger emerged clearly once the data had been structured. None of that analysis was performed by the model. It handled the reading; we handled the thinking.
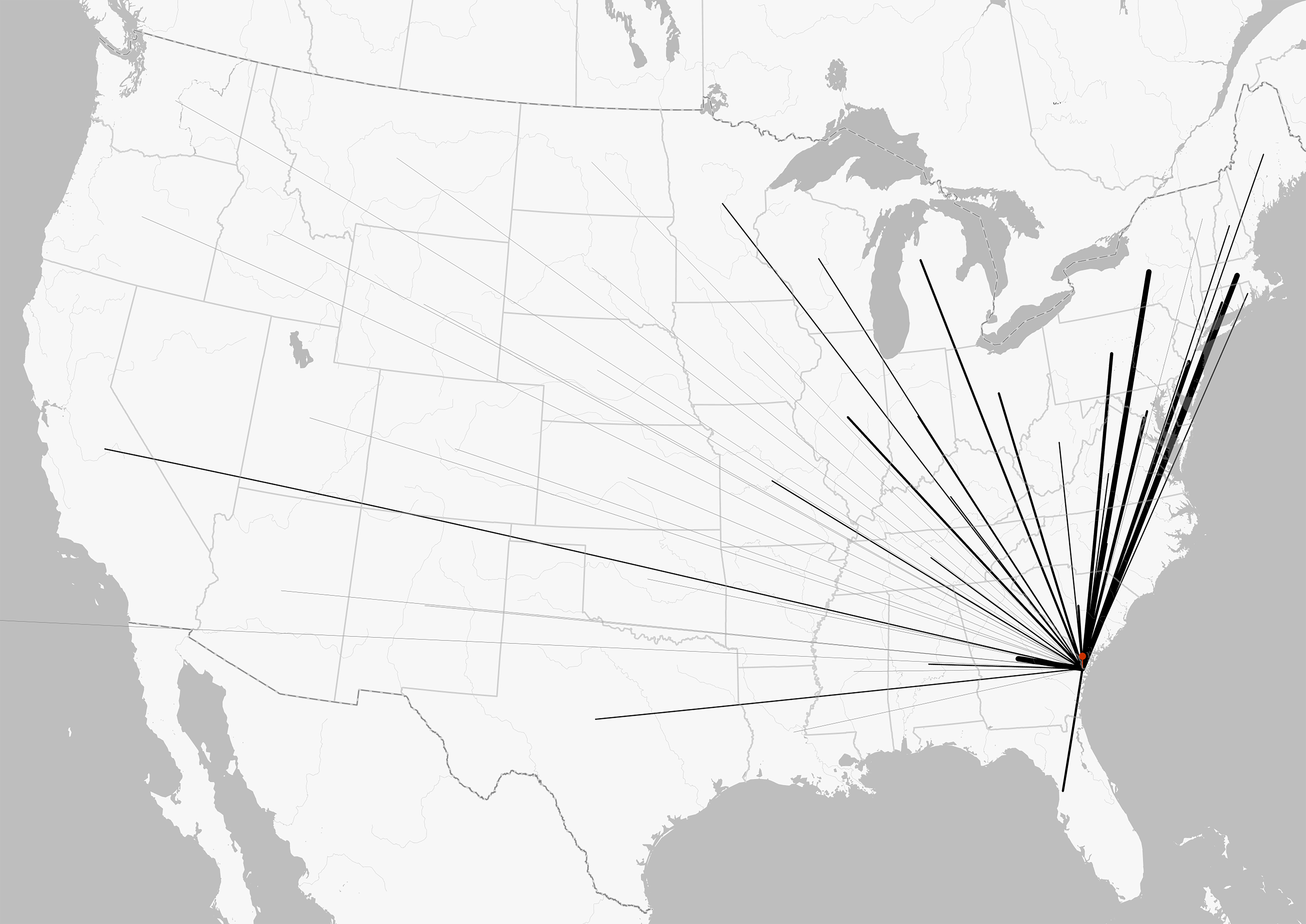
Seen in this light, tools like these do not promise automated history. They promise a reallocation of effort. Tasks that once required weeks of mechanical transcription can now be accelerated, leaving more room for the questions that brought us to the archive in the first place. For the Hermitage register, those questions are just beginning—about who visited, why they came, and what a guest book from a plantation-turned-tourist-site can tell us about how Americans in the 1930s chose to encounter the history of slavery.
Related article: https://doi.org/10.1080/15420353.2026.2614780
 | A guest post by
|
Amazing post 🙌🏽